Today we learnt: Every linear operator 

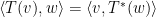
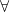
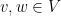
How is 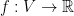


-
where
is an orthonormal basis for
.
This result tells the relation between the matrix representations of
- If
, then
is symmetric.
Below we shall see that self-adjoint operator
Recall that for linear operators on vector spaces, we study the concept of similarity and diagonalization: let us review a few important points below. By definition, “

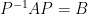

- If
is a linear operator on vector space (not necessarily inner product space), then
is similar to
for any ordered bases
and
.
- If
Next suppose 
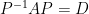
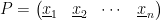


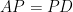
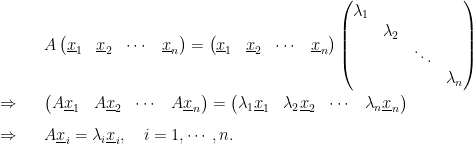
That means 


Furthermore, we can present the above result in the setting of linear transformation: Suppose 
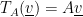

![{\mathcal{E}=[\underline{x}_1,\cdots, \underline{x}_n]}](https://s0.wp.com/latex.php?latex=%7B%5Cmathcal%7BE%7D%3D%5B%5Cunderline%7Bx%7D_1%2C%5Ccdots%2C+%5Cunderline%7Bx%7D_n%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
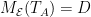
is similar to a diagonal matrix  There exists a basis
There exists a basis  for such that
for such that 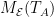 is diagonal There exists a basis for such that
is diagonal There exists a basis for such that  ,
, 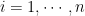 We can find a basis consisting of eigenvectors of for
We can find a basis consisting of eigenvectors of for
Now we turn back to inner product spaces. If

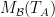
In terms of matrices, this is equivalent to finding a set of orthonormal eigenvectors
Here we make a nice observation: if 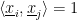
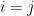


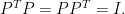
Such a matrix is called an orthogonal matrix (i.e. 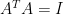
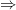

Hence for our problem 

Now we can state the following key result for self-adjoint linear operators (or in matrix setting, symmetric matrices):
Every
symmetric matrix
In the setting of linear operators, every self-adjoint operator
See also Lect28-29.pdf in the folder slides.
 has only 1 eigenvalue
has only 1 eigenvalue  for some nonsingular
for some nonsingular  . Then,
. Then,
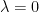 and
and  , then
, then  .
. 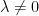 and
and  , then
, then  .
.  and
and  , then
, then  .
.  .
.  , then
, then
 (zero matrix).
(zero matrix).  has no real solution, does it mean
has no real solution, does it mean  ,
,  .
.

 is similar to
is similar to 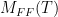 .
. is an eigenvalue of
is an eigenvalue of  .
.
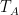 . We get a pair of bases
. We get a pair of bases  and
and  in
in  .
.
 and
and 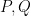 such that
such that 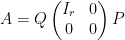 .
.
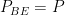 and
and 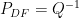 .
.
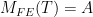 (which can be seen by using the basis change theorem in p.1).
(which can be seen by using the basis change theorem in p.1). if
if  . By
. By  and
and  equal
equal  ; thus
; thus  and
and  ?
?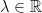 and
and 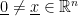 satisfy
satisfy 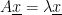 , then
, then  is said to be an eigenvector of
is said to be an eigenvector of 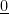 is NOT an eigenvector of
is NOT an eigenvector of 
 the eigenspace of
the eigenspace of 
 of degree
of degree  . (
. (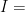 the
the 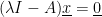
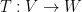 by a matrix. Remember that we need to fix an ordered basis
by a matrix. Remember that we need to fix an ordered basis  in order to represent
in order to represent  . Given that
. Given that 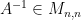 exists, and
exists, and 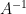 induces a linear tranformation
induces a linear tranformation  ,
, 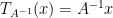 where
where  .
.
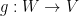 by
by 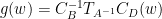 for any
for any  .
.
 and
and  .
.
 .
. 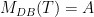 .
.  .
.
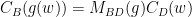 ,
,  (i.e.
(i.e. 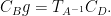
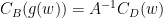
 ,
, ![{D=[d_1,\cdots, d_n]}](https://s0.wp.com/latex.php?latex=%7BD%3D%5Bd_1%2C%5Ccdots%2C+d_n%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) .
.  , then
, then  .
.  and
and  , we get
, we get 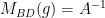 .
.
 (the
(the 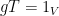 .
. 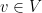 ,
, 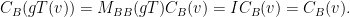
 is an isomorphism,
is an isomorphism, 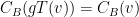 implies
implies 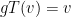 , which holds for all
, which holds for all 
 .
.
 induces a linear transformation
induces a linear transformation  (defined by
(defined by 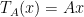 ),
),
 can be represented by a matrix
can be represented by a matrix 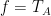 . (See Lect16a.pdf)
. (See Lect16a.pdf)
 be a basis for
be a basis for  is a basis for
is a basis for  . Then
. Then 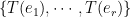 is a basis for
is a basis for  .
.
 are linearly independent.
are linearly independent.
 . By linearity,
. By linearity,  .
. 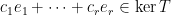 .
. 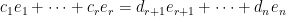
 .
.  .
. is a basis (so is linearly independent),
is a basis (so is linearly independent), 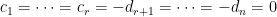 .
.  is the possible coefficients such that
is the possible coefficients such that  . Then
. Then 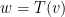 for some
for some  .
. 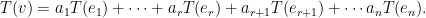
 ,
,  .
.  .
.
 . Then
. Then 
 , the preimage of
, the preimage of  .]
.]
 and
and 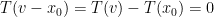 , i.e.
, i.e.  so
so  for some
for some  .
.  . This completes the proof.
. This completes the proof. and the column space
and the column space 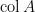 of a matrix
of a matrix  ) induced by a matrix
) induced by a matrix 
 of a linear transformation
of a linear transformation 